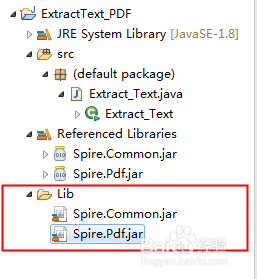
1、首先,在Java程序中新建一个文件夹可命名为Lib。下载控件包后,解压,将解压后的文件夹下的子文件夹lib中的Spire.Pdf.jar和Spire.Common.jar两个文件复制到新建的文件夹下,如下图:
2、建好文件夹后,引用两个文件:选中这两个文件,任意点击其中之一,选择“Build Path” – “Add to Build Path”。

1、 //创建PdfDocument实例
PdfDocument doc = new PdfDocument();
//加载PDF文件
doc.loadFromFile("sample.pdf");
//创建StringBuilder实例
StringBuilder sb = new StringBuilder();
PdfPageBase page;
//遍历PDF页面,获取每个页面的文本并添加到StringBuilder对象
for(int i= 0;i<doc.getPages().getCount();i++){
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//将StringBuilder对象中的文本写入到文本文件
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
2、测试文档:

3、读取结果: